Explore Kubernetes Design inspired by Borg
Google released a detailed paper on Borg in 2015, titled Large-scale cluster management at Google with Borg. Borg plays a vital role in managing clusters in Google, overseeing numerous machines, efficiently distributing workloads among them, and ensuring optimal resource allocation.
The architectural design of Borg, as shown in the image below directly from the paper, bears a notable resemblance to Kubernetes. This similarity is expected, given Kubernetes drew inspiration from Borg’s architecture.
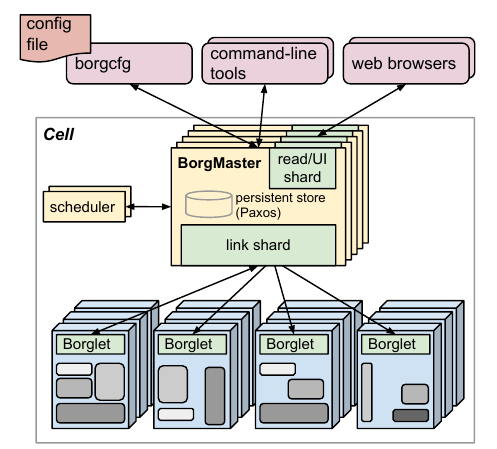
A basic comparison can be made between the components in Borg and Kubernetes, providing a foundational understanding of their operational structures.
| Borg Component | Kubernetes Component |
|---|---|
| Borgmaster | etcd + API server + controller |
| Scheduler | kube-scheduler |
| BorgMaster | kubelet |
In the following sections, I will explore several key design principles in Kubernetes that was influenced by Borg. Despite Borg’s closed-source nature, the paper shed light on the operational intricacies of the Borg system.
The Significance of Pods
Borg’s initial goal was to optimize resource utilization, such as CPU and memory, within a cluster. Borg addressed this challenge by integrating both latency-sensitive applications and batch jobs into a unified cluster, scheduling them collectively to maximize resource utilization.
In Borg, a job consists of a collection of tasks, with each task comprising a set of processes.
However, in scenarios where machine resources are scarce, latency-sensitive applications take precedence over batch jobs. To ensure specific batch jobs receive guaranteed resource allocation without interruptions, Borg introduced the concept of an alloc, short for allocation. An alloc reserves resources for a particular job, allowing the job to utilize them as needed. Notably, tasks within the same alloc often collaborate to deliver functionalities; for example, one task could serve as a web server while another generates content.
Kubernetes adopted the essence of alloc from Borg with the introduction of pods. A pod represents a group of containers scheduled together on a single machine, sharing resources like the network namespace. Through the use of pods, Kubernetes enables collaborative containers to implement the “co-working tasks” pattern effectively.
The Role of Labels in Pods
In Borg, managing a multi-job service as a cohesive entity was challenging due to the rigid job-task relationship. This limitation fell short in real-world scenarios, making tasks like identifying all jobs/tasks operating within the canary environment difficult.
In contrast, Kubernetes departed from Borg’s job-centric approach by directly overseeing tasks, or pods. Pods are organized using labels, offering a more flexible structure compared to Borg’s job-task relationship. This label-based system provides users with increased flexibility and control over their application design.
Pods with Unique IPs
In Borg, tasks on the same host shared the same IP address within the host networking namespace, leading to port management complexities. Users had to allocate ports for each task, introducing inefficiencies.
Kubernetes assigns a unique IP address to each pod, facilitating inter-pod communication without Network Address Translation (NAT). This design choice simplifies port management for developers, allowing them to configure applications to use standard ports like 80 for HTTP, streamlining development and debugging processes.
During Borg’s inception, the absence of network namespaces in the Linux kernel and the early stage of Software Defined Networking (SDN) made port allocation more of a workaround than a fundamental design flaw.
The Evolution to a Non-Monolithic Master
Initially conceived as a monolithic system, the Borgmaster underwent a transformation as additional features were integrated, leading to its division into distinct components such as the scheduler and the primary UI.
In Kubernetes, this design evolution was further refined by segmenting the control plane into:
- etcd: serving as the backend distributed key-value store.
- API server: functioning as the control plane’s frontend, presenting Objects as the interface between users and the Kubernetes cluster.
- Controller: acting as a consumer of the API server and overseeing the cluster’s state.
By establishing a stable contract through Objects in the API server, users find it easier to articulate their requirements and develop programs for managing these objects and the entire cluster. This practice aligns with a prevalent pattern in Kubernetes programming known as the operator pattern.
Further Exploration
In addition to the Borg paper, Google has also released a document detailing the system’s progression from Borg to Kubernetes, titled Borg, Omega, and Kubernetes.